# A tibble: 6 × 9
id T.start T.stop A D L X A0 L0
<int> <int> <dbl> <int> <int> <dbl> <int> <int> <dbl>
1 1 0 1 0 0 -1.43 0 0 -1.43
2 1 1 2 1 0 -0.603 0 0 -1.43
3 1 2 2.21 1 0 1.10 0 0 -1.43
4 2 0 1 1 0 2.10 0 1 2.10
5 2 1 2 0 0 -1.39 0 1 2.10
6 2 2 2.5 0 0 -1.96 0 1 2.101 G-computation
Objectif - Question 1
Cette partie répond à la Question 1 : quel serait l’effet d’une exposition initiale universelle (\(a_0 = 1\) pour tous) par rapport à une absence totale d’exposition (\(a_0 = 0\) pour tous) ?
On souhaite estimer les courbes de survie contrefactuelles :
\[S^{a_0=1}(t) = P(T^{a_0=1} > t) \quad \text{et} \quad S^{a_0=0}(t) = P(T^{a_0=0} > t)\]
La méthode utilisée ici est la G-computation (standardisation par régression) : on modélise le résultat \(Y\) en fonction de l’exposition et des covariables, puis on prédit les devenirs contrefactuels pour l’ensemble de la population.
Note
Simplification pédagogique : pour cette partie, le critère de jugement est traité comme binaire (décès en fin de suivi, oui/non) : on estime \(\widehat{P}(D=1 \mid a_0=1)\) et \(\widehat{P}(D=1 \mid a_0=0)\), c’est-à-dire deux proportions de décès contrefactuelles. On peut effectuer une G-computation pour estimer directement la courbe de survie complète, mais c’est techniquement plus complexe (une section bonus en bas de cette page en montre la mise en œuvre, à consulter et à faire chez vous). La Partie 2 traitera le critère censuré directement via l’IPTW.
Note sur la session R
Les variables suivantes sont disponibles dans vos chunks interactifs (construites dans le contexte de setup) :
-
df: base de données au format long, avecA0(exposition initiale, valeur deAà \(t=0\)) etL0(facteur de confusion initial, valeur deLà \(t=0\))
Les premières lignes de df illustrent ce format long et montrent les colonnes A0 et L0 :
Étape 0 - Créer la base baseline
La G-computation s’applique sur une base une ligne par individu, avec les valeurs initiales des covariables et le statut final.
Créez df_base contenant : id, A0, L0, X, time (temps total de suivi = dernière valeur de T.stop), et D (statut final = dernière valeur de D).
Montrez moi comment faire !
## On résume df (format long) en une ligne par individu :
## - first() pour les covariables mesurées à t=0
## - last() pour le temps de suivi total et le statut final
df_base <- df |>
group_by(id) |>
summarise(
A0 = first(A), # exposition initiale
L0 = first(L), # facteur de confusion initial
X = first(X), # covariable initiale
time = last(T.stop), # temps total de suivi
D = last(D) # décès (0/1) : statut en fin de suivi
)
head(df_base)
nrow(df_base) # doit valoir le nombre d'individus distinctsVoir le résultat
# A tibble: 6 × 6
id A0 L0 X time D
<int> <int> <dbl> <int> <dbl> <int>
1 1 0 -1.43 0 2.21 0
2 2 1 2.10 0 2.5 0
3 3 0 -0.0163 0 2.17 1
4 4 0 -0.167 0 0.5 0
5 5 1 0.219 0 0.51 0
6 6 1 0.834 0 0.96 0[1] 2000La base comporte 2000 lignes (une par individu). La variable D indique si l’individu est décédé avant la fin du suivi (3 ans).
Étape 1 - Estimer les modèles de résultat
La G-computation ajuste le modèle d’outcome (\(D\)) séparément selon le groupe d’exposition \(A_0\), en contrôlant pour les facteurs de confusion \(X\) et \(L_0\).
Estimez deux modèles de régression logistique sur D : mod1 sur les individus avec A0 = 1, mod0 sur les individus avec A0 = 0.
Montrez moi comment faire !
## Régression logistique sur D dans chaque groupe d'exposition séparément :
## on ajuste sur X et L0 pour contrôler la confusion
## (deux modèles séparés = équivalent à une interaction complète avec A0)
mod1 <- glm(D ~ X + L0,
data = df_base[df_base$A0 == 1, ],
family = binomial) # critère binaire -> famille binomiale (logit)
mod0 <- glm(D ~ X + L0,
data = df_base[df_base$A0 == 0, ],
family = binomial)
summary(mod1)
summary(mod0)Voir le résultat
Call:
glm(formula = D ~ X + L0, family = binomial, data = df_base[df_base$A0 ==
1, ])
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -2.3484 0.1672 -14.046 < 2e-16 ***
X 0.6416 0.2314 2.772 0.005565 **
L0 0.4580 0.1237 3.701 0.000215 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 600.39 on 726 degrees of freedom
Residual deviance: 571.55 on 724 degrees of freedom
AIC: 577.55
Number of Fisher Scoring iterations: 5
Call:
glm(formula = D ~ X + L0, family = binomial, data = df_base[df_base$A0 ==
0, ])
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -1.27224 0.08882 -14.324 < 2e-16 ***
X 0.34157 0.14414 2.370 0.0178 *
L0 0.43931 0.07712 5.696 1.22e-08 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 1399.5 on 1272 degrees of freedom
Residual deviance: 1344.2 on 1270 degrees of freedom
AIC: 1350.2
Number of Fisher Scoring iterations: 4Étape 2 - Prédire les devenirs contrefactuels
Pour chaque individu (quelle que soit son exposition réelle), on prédit le risque de décès comme s’il avait été exposé (via mod1) et comme s’il n’avait pas été exposé (via mod0).
Calculez les vecteurs y1 et y0 : probabilités de décès prédites sous \(a_0=1\) et \(a_0=0\).
Montrez moi comment faire !
## Probabilité de décès si tout le monde avait A0 = 1
y1 <- predict(mod1, newdata = df_base, type = "response")
## Probabilité de décès si tout le monde avait A0 = 0
y0 <- predict(mod0, newdata = df_base, type = "response")
head(data.frame(id = df_base$id, A0_obs = df_base$A0,
pred_A0_1 = round(y1, 3),
pred_A0_0 = round(y0, 3)))Voir le résultat
id A0_obs pred_A0_1 pred_A0_0
1 1 0 0.047 0.130
2 2 1 0.200 0.413
3 3 0 0.087 0.218
4 4 0 0.081 0.207
5 5 1 0.096 0.236
6 6 1 0.123 0.288Étape 3 - Calculer l’effet causal moyen (ATE)
Calculez \(\widehat{E}(Y^1) = \overline{y_1}\), \(\widehat{E}(Y^0) = \overline{y_0}\), puis l’ATE et le RR.
Voir le résultat
E(D^1) = 0.125 E(D^0) = 0.26 ATE = E(D^1) - E(D^0) = -0.135 RR = E(D^1) / E(D^0) = 0.48 On obtient : \(\widehat{E}(Y^1) \approx\) 0.125, \(\widehat{E}(Y^0) \approx\) 0.26, \(\widehat{ATE} \approx\) -0.135.
Interprétation
Que signifie cet ATE ? Comment le comparez-vous à l’analyse brute de la page précédente ?
AstuceRéponse
L’ATE estimé par G-computation est la différence de risque de décès entre les scénarios contrefactuels “tout le monde exposé” et “personne exposé”, après ajustement sur \(X\) et \(L_0\).
Contrairement à l’analyse brute, cette estimation tient compte du fait que les individus exposés et non exposés ne sont pas comparables à l’inclusion.
Points à retenir :
- On traite le décès comme binaire, en ignorant l’information temporelle (voir le bonus en bas de page pour la version survie complète).
- On n’ajuste que sur les confondeurs initiaux, ce qui est suffisant ici : la question porte sur l’exposition initiale \(A_0\). La Partie 3 traitera les confondeurs dépendants du temps dans le cadre de l’analyse per-protocol.
- L’estimation repose entièrement sur la bonne spécification du modèle d’outcome \(D\).
La Partie 2 répondra à la même Question 1 en utilisant une approche différente (IPTW), ce qui permettra un contrôle croisé des deux estimations.
Pour continuer, cliquez sur IPTW dans le menu à gauche.
BONUS - Intervalle de confiance par bootstrap
Note
Cette section est à faire chez vous, à votre rythme. Elle n’est pas traitée en TP.
Le bootstrap sert ici uniquement à estimer un intervalle de confiance autour de l’ATE calculé à l’Étape 3 : il ne modifie pas l’estimation elle-même.
Estimez un intervalle de confiance à 95% par bootstrap (\(B = 200\) ré-échantillons).
Montrez moi comment faire !
set.seed(123)
B <- 200
ate_boot <- numeric(B)
for (b in 1:B) {
## Ré-échantillonnage avec remise (même taille que df_base)
idx <- sample(nrow(df_base), replace = TRUE)
df_b <- df_base[idx, ]
## Réajuster les deux modèles sur l'échantillon bootstrap
m1 <- glm(D ~ X + L0, data = df_b[df_b$A0 == 1, ], family = binomial)
m0 <- glm(D ~ X + L0, data = df_b[df_b$A0 == 0, ], family = binomial)
## Prédire pour tous les individus du bootstrap sous chaque scénario
y1_b <- predict(m1, newdata = df_b, type = "response")
y0_b <- predict(m0, newdata = df_b, type = "response")
## Stocker l'ATE de cet échantillon bootstrap
ate_boot[b] <- mean(y1_b) - mean(y0_b)
}
## L'ATE est celui estimé à l'Étape 3 (E_Y1 - E_Y0), pas la moyenne des bootstrap
cat("ATE :", round(E_Y1 - E_Y0, 3), "\n")
cat("IC 95% :", round(quantile(ate_boot, c(0.025, 0.975)), 3), "\n")Voir le résultat
ATE : -0.135 IC 95% : -0.171 -0.097 BONUS 2 - G-computation sur critère censuré
Note
Cette section est à faire chez vous, à votre rythme. Elle n’est pas traitée en TP. Elle montre comment étendre la G-computation vue précédemment pour traiter correctement le critère de jugement censuré.
Pourquoi changer d’approche ?
La G-computation de la partie principale modélise \(D\) comme un indicateur binaire (décédé avant \(t = 3\) ans, oui/non). Deux limites importantes :
- Information temporelle perdue : on sait si l’individu est décédé, mais on ignore quand.
- Censure traitée comme un non-événement : un individu perdu de vue à \(t = 1\) an est traité de la même façon qu’un individu suivi 3 ans sans événement.
On peut effectuer une G-computation pour estimer directement des courbes de survie contrefactuelles :
\[\hat{S}^{a_0 = 1}(t) = P(T^{a_0=1} > t) \qquad \text{et} \qquad \hat{S}^{a_0 = 0}(t) = P(T^{a_0=0} > t)\]
Principe
Deux approches sont possibles : estimer deux modèles de Cox séparément (un chez les exposés, un chez les non-exposés), ou estimer un seul modèle incluant une interaction entre \(A_0\) et les covariables \((X, L_0)\). Nous retenons la seconde, plus synthétique.
Le modèle estimé sur l’ensemble de la population est :
\[h(t; A_0, X, L_0) = h_0(t) \cdot \exp\!\left(\beta_1 A_0 + \beta_2 X + \beta_3 L_0 + \beta_{12} A_0 X + \beta_{13} A_0 L_0\right)\]
Pour obtenir les courbes contrefactuelles, on prédit le prédicteur linéaire \(\hat{\text{lp}}_i\) pour chaque individu dans deux bases contrefactuelles (tous exposés : \(A_0=1\), tous non-exposés : \(A_0=0\)), puis on calcule la survie individuelle :
\[\hat{S}_i^{a_0}(t) = \exp\!\left(- \hat{H}_0(t) \times e^{\,\hat{\text{lp}}_i^{a_0}}\right)\]
- \(\hat{H}_0(t)\) : hazard cumulatif de base (estimateur de Breslow), commun à toute la population
- \(e^{\,\hat{\text{lp}}_i^{a_0}}\) : multiplicateur individuel de risque sous le scénario \(a_0\)
La courbe de survie marginale (contrefactuelle) s’obtient en moyennant sur l’ensemble de la population :
\[\hat{S}^{a_0}(t) = \frac{1}{n} \sum_{i=1}^n \hat{S}_i^{a_0}(t)\]
Étape 1 - Un modèle de Cox avec interaction
Note
df_base doit avoir été créée lors de l’Étape 0 ci-dessus. Si nécessaire, relancez ce chunk d’abord.
Estimez un modèle de Cox sur l’ensemble de la population, avec une interaction entre \(A_0\) et les covariables \((X, L_0)\). Utilisez coxph(Surv(time, D) ~ A0 * (X + L0), data = df_base).
Montrez moi comment faire !
## Un seul modèle de Cox avec interaction A0 × covariables.
## Hypothèse : les deux groupes partagent le même risque de base h0(t).
## Deux modèles séparés lèveraient cette contrainte.
## Surv(time, D) : time = temps de suivi total, D = indicateur de décès
mod_cox <- coxph(Surv(time, D) ~ A0 * (X + L0), data = df_base)
summary(mod_cox)Voir le résultat
Call:
coxph(formula = Surv(time, D) ~ A0 * (X + L0), data = df_base)
n= 2000, number of events= 409
coef exp(coef) se(coef) z Pr(>|z|)
A0 -1.03310 0.35590 0.17331 -5.961 2.51e-09 ***
X 0.22568 1.25317 0.12346 1.828 0.0676 .
L0 0.50638 1.65927 0.06975 7.260 3.88e-13 ***
A0:X 0.39391 1.48277 0.24343 1.618 0.1056
A0:L0 -0.05794 0.94370 0.13130 -0.441 0.6590
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
exp(coef) exp(-coef) lower .95 upper .95
A0 0.3559 2.8098 0.2534 0.4999
X 1.2532 0.7980 0.9838 1.5963
L0 1.6593 0.6027 1.4473 1.9023
A0:X 1.4828 0.6744 0.9202 2.3894
A0:L0 0.9437 1.0597 0.7296 1.2207
Concordance= 0.673 (se = 0.014 )
Likelihood ratio test= 136.1 on 5 df, p=<2e-16
Wald test = 131.4 on 5 df, p=<2e-16
Score (logrank) test = 139.2 on 5 df, p=<2e-16Étape 2 - Hazard cumulatif de base et prédicteurs linéaires individuels
L’estimation des courbes contrefactuelles nécessite deux ingrédients :
- Le hazard cumulatif de base \(\hat{H}_0(t)\) : c’est une fonction en escalier qui augmente à chaque temps d’événement. On l’obtient avec
basehaz(mod_cox, centered = FALSE), qui renvoie un data frame avec les colonnestimeethazard. - Le prédicteur linéaire individuel \(\hat{\text{lp}}_i^{a_0}\) : calculé dans deux bases contrefactuelles : l’une où tous les individus ont \(A_0=1\), l’autre où tous ont \(A_0=0\). On l’obtient avec
predict(mod_cox, newdata = ..., type = "lp").
Créez les bases contrefactuelles df1 (A0=1 pour tous) et df0 (A0=0 pour tous), extrayez le hazard cumulatif de base, et calculez les prédicteurs linéaires sous chaque scénario.
Montrez moi comment faire !
## Bases contrefactuelles
df1 <- df_base; df1$A0 <- 1
df0 <- df_base; df0$A0 <- 0
## Hazard cumulatif de base unique (estimateur de Breslow)
## centered = FALSE : hazard de base au niveau de référence (X=0, L0=0, A0=0)
## suppressWarnings : Cox avec interaction génère un avertissement sans danger
bh <- suppressWarnings(basehaz(mod_cox, centered = FALSE))
head(bh) # time = temps d'événement, hazard = H0(t) cumulé
## Prédicteurs linéaires individuels sous chaque scénario contrefactuel
lp1 <- predict(mod_cox, newdata = df1, type = "lp")
lp0 <- predict(mod_cox, newdata = df0, type = "lp")
head(data.frame(
id = df_base$id,
A0_obs = df_base$A0,
lp_si_A1 = round(lp1, 3),
lp_si_A0 = round(lp0, 3)
))Voir le résultat
hazard time
1 0.000000000 0.01
2 0.001030907 0.02
3 0.001030907 0.03
4 0.001030907 0.04
5 0.001030907 0.05
6 0.002591204 0.06 id A0_obs lp_si_A1 lp_si_A0
1 1 0 -1.731 -0.781
2 2 1 -0.151 1.003
3 3 0 -1.099 -0.067
4 4 0 -1.166 -0.143
5 5 1 -0.993 0.052
6 6 1 -0.718 0.364Étape 3 - Courbes de survie individuelles et marginalisation
On dispose maintenant de tout ce qu’il faut pour calculer \(\hat{S}_i^{a_0}(t)\) pour chaque individu \(i\) et chaque temps \(t\), puis d’en faire la moyenne.
Astuce
stepfun(knots, values) crée une fonction en escalier à partir des nœuds et valeurs associées. Ici, stepfun(bh1$time, c(0, bh1$hazard)) crée la fonction \(\hat{H}_0^{(a_0=1)}(t)\) : elle vaut 0 avant le premier événement, puis prend la valeur de Breslow correspondante à chaque nœud. On peut ensuite l’évaluer sur n’importe quelle grille de temps.
outer(u, v) calcule le produit extérieur de deux vecteurs : outer(u, v)[i, j] = u[i] * v[j]. Cela permet de calculer \(-e^{\hat{\text{lp}}_i} \times \hat{H}_0(t_j)\) pour tous les couples \((i, j)\) d’un coup, sans boucle, et d’obtenir directement la matrice des \(n \times T\) valeurs \(\log \hat{S}_i(t_j)\).
Calculez les courbes de survie marginales \(\hat{S}^{a_0=1}(t)\) et \(\hat{S}^{a_0=0}(t)\) sur une grille de temps.
Montrez moi comment faire !
## 1. Grille de temps : tous les temps d'événement de df_base
t_grid <- sort(unique(df_base$time))
## 2. H0(t) unique évalué sur t_grid via une fonction en escalier
## stepfun crée une fonction en escalier : c(0, bh$hazard) indique que
## le hazard cumulatif vaut 0 avant le premier temps d'événement
H_fun <- stepfun(bh$time, c(0, bh$hazard))
H_grid <- H_fun(t_grid) # vecteur longueur T
## 3. Survie individuelle : S_i(t_j) = exp(-H0(t_j) * exp(lp_i))
## outer(-exp(lp), H_grid)[i, j] = -exp(lp[i]) * H_grid[j]
S1_mat <- exp(outer(-exp(lp1), H_grid)) # matrice n × T, scénario a0=1
S0_mat <- exp(outer(-exp(lp0), H_grid)) # matrice n × T, scénario a0=0
## 4. Courbes marginales : moyenne sur les individus (ligne = individu)
S1_marg <- colMeans(S1_mat)
S0_marg <- colMeans(S0_mat)
head(data.frame(t = round(t_grid, 2),
S_a1 = round(S1_marg, 3),
S_a0 = round(S0_marg, 3)))Voir le résultat
t S_a1 S_a0
1 0.01 1.000 1.000
2 0.02 0.999 0.999
3 0.03 0.999 0.999
4 0.04 0.999 0.999
5 0.05 0.999 0.999
6 0.06 0.999 0.997Étape 4 - Visualisation des courbes de survie contrefactuelles
Tracez les deux courbes de survie marginales contrefactuelles sur le même graphique.
Montrez moi comment faire !
## type = "s" : courbe en escalier, adaptée aux estimateurs de survie discrets
plot(t_grid, S1_marg, type = "s", col = "blue", lwd = 2,
ylim = c(0, 1),
xlab = "Temps (années)",
ylab = "Probabilité de survie",
main = "G-computation (Cox) - Courbes contrefactuelles")
lines(t_grid, S0_marg, type = "s", col = "red", lwd = 2)
legend("bottomleft",
legend = expression(
"Scénario " ~ a[0] * "=1 (tous exposés)",
"Scénario " ~ a[0] * "=0 (aucun exposé)"
),
col = c("blue", "red"), lty = 1, lwd = 2, bty = "n")Voir le résultat
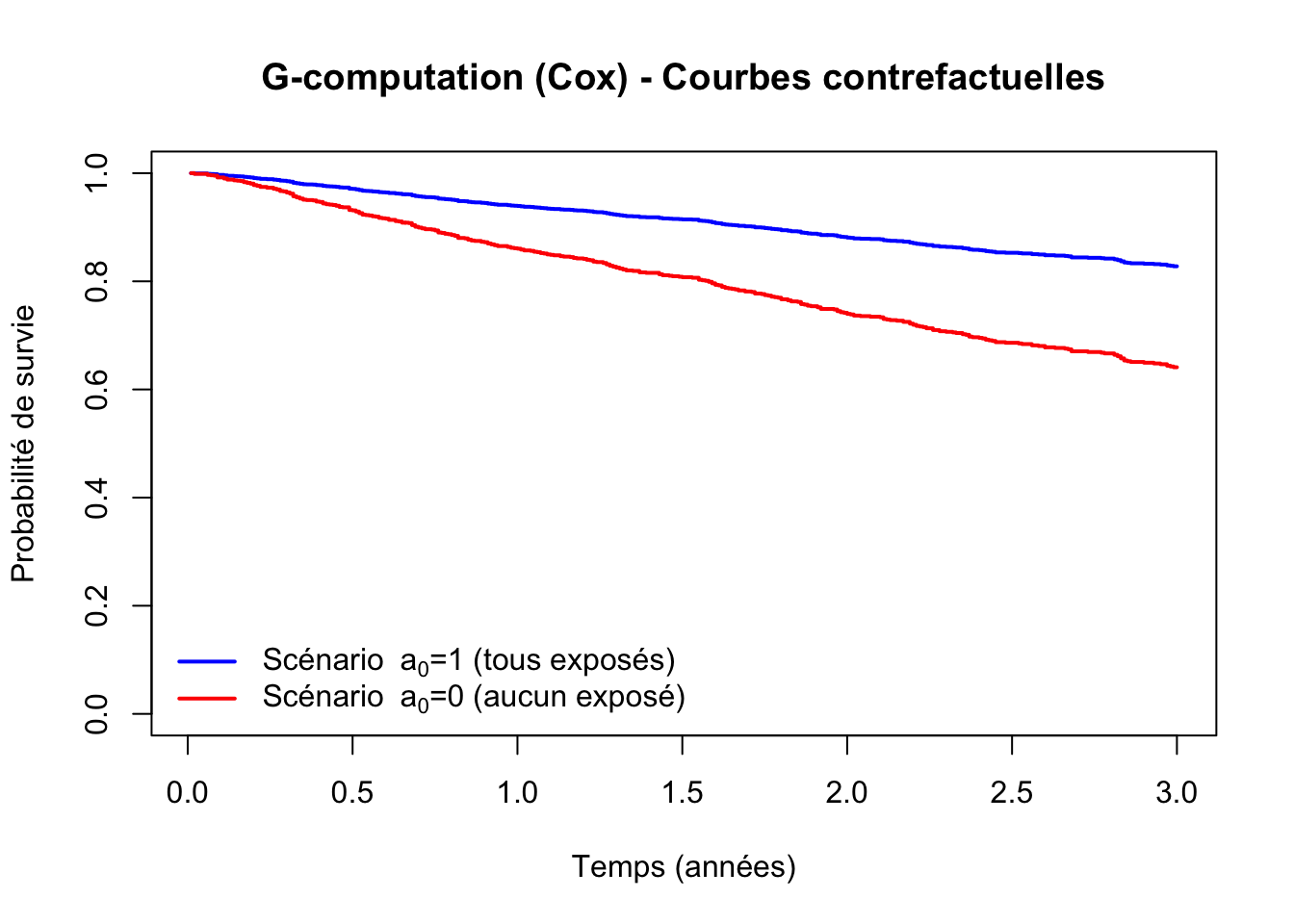
Étape 5 - Différence de survie à \(t = 3\) ans
Calculez \(\hat{S}^{a_0=1}(3)\), \(\hat{S}^{a_0=0}(3)\), et la différence de survie à 3 ans. Comparez avec l’ATE obtenu par G-computation logistique.
Montrez moi comment faire !
## t_grid ne contient pas nécessairement exactement t=3 : on prend
## le dernier temps d'événement inférieur ou égal à 3
idx3 <- max(which(t_grid <= 3))
S1_3 <- S1_marg[idx3]
S0_3 <- S0_marg[idx3]
cat("S^(a0=1)(3) =", round(S1_3, 3), "\n")
cat("S^(a0=0)(3) =", round(S0_3, 3), "\n")
cat("Différence de survie à 3 ans :", round(S1_3 - S0_3, 3), "\n")
cat("Rapport de survie à 3 ans :", round(S1_3 / S0_3, 3), "\n")Voir le résultat
S^(a0=1)(3) = 0.828 S^(a0=0)(3) = 0.641 Différence de survie à 3 ans : 0.187 Rapport de survie à 3 ans : 1.291
AstuceDiscussion - comparaison avec l’approche binaire
À titre indicatif, avec ce jeu de données : \(\hat{S}^{a_0=1}(3) \approx\) 0.828, \(\hat{S}^{a_0=0}(3) \approx\) 0.641, différence de survie \(\approx\) 0.187.
Les deux G-computations (logistique et Cox) ciblent en principe le même estimand : \(P(T^{a_0} \leq 3)\), ce qui correspond à \(1 - S^{a_0}(3)\). En pratique, la différence de survie à \(t = 3\) obtenue par les deux méthodes est souvent proche, mais peut légèrement différer car :
- la version Cox utilise toute l’information temporelle (pas seulement le statut binaire à 3 ans) ;
- la version Cox traite correctement la censure : un individu censuré à \(t = 1\) an ne contribue qu’à l’estimation jusqu’à son temps de censure, sans être compté comme “survivant” ou “décédé” à 3 ans ;
- les deux modèles imposent des hypothèses fonctionnelles différentes (effets proportionnels des hazards pour Cox, effets log-linéaires sur la cote pour la logistique).
La version Cox est donc plus rigoureuse et constitue l’approche standard pour la G-computation avec un critère de survie.
Intervalle de confiance par bootstrap (modèle de Cox)
Estimez un intervalle de confiance à 95% par bootstrap (\(B = 200\) ré-échantillons) pour la différence de survie à \(t = 3\) ans.
Montrez moi comment faire !
set.seed(42)
B <- 200
S1_boot <- numeric(B)
S0_boot <- numeric(B)
for (b in 1:B) {
## 1. Ré-échantillonnage avec remise
idx <- sample(nrow(df_base), replace = TRUE)
db <- df_base[idx, ]
## 2. Modèle de Cox avec interaction sur l'échantillon bootstrap
m <- suppressWarnings(coxph(Surv(time, D) ~ A0 * (X + L0), data = db))
## 3. Bases contrefactuelles, hazard de base et prédicteurs linéaires
db1 <- db; db1$A0 <- 1
db0 <- db; db0$A0 <- 0
bhb <- suppressWarnings(basehaz(m, centered = FALSE))
lp1b <- predict(m, newdata = db1, type = "lp")
lp0b <- predict(m, newdata = db0, type = "lp")
## 4. H0(3) : dernier hazard cumulatif <= 3 (0 si aucun événement avant 3 ans)
H_3b <- if (any(bhb$time <= 3)) tail(bhb$hazard[bhb$time <= 3], 1) else 0
## S_i(3) = exp(-H0(3) * exp(lp_i)), puis moyenne sur les individus
S1_boot[b] <- mean(exp(-H_3b * exp(lp1b)))
S0_boot[b] <- mean(exp(-H_3b * exp(lp0b)))
}
diff_boot <- S1_boot - S0_boot
## L'estimée est celle calculée avant le bootstrap (S1_3 - S0_3)
## Le bootstrap ne sert qu'à l'intervalle de confiance
cat("Différence de survie à 3 ans (G-computation Cox) :\n")
cat(" Estimée :", round(S1_3 - S0_3, 3), "\n")
cat(" IC 95% :", round(quantile(diff_boot, c(0.025, 0.975)), 3), "\n")Voir le résultat
Différence de survie à 3 ans (G-computation Cox) : Estimée : 0.187 IC 95% : 0.14 0.221