Cette partie répond à la même Question 1 que la G-computation : estimer les courbes de survie contrefactuelles \(S^{a_0=1}(t)\) et \(S^{a_0=0}(t)\) ajustées sur les facteurs de confusion \(X\) et \(L_0\).
L’IPTW adopte une stratégie opposée à la G-computation : au lieu de modéliser le résultat \(Y\), il modélise l’exposition\(A_0\) conditionnellement aux covariables, puis pondère les individus pour créer une pseudo-population équilibrée. Une fois les poids calculés, l’analyse de survie est directement réalisée par Kaplan-Meier pondéré, ce qui traite correctement la censure, de même que la G-computation de la courbe de survie présentée dans le bonus de la Partie 1. La simplification binaire de la Partie 1 avait été faite uniquement pour des raisons pédagogiques.
Note
Lien avec la Partie 1 : la G-computation avait traité \(D\) comme une variable binaire (décédé avant 3 ans, oui/non) pour simplifier. Avec l’IPTW, l’implémentation est tout aussi simple avec le critère censuré. Des notes repliables proposent le code et les résultats équivalents en version binaire, pour comparer directement les deux méthodes à la fin.
La variable df est disponible dans les chunks interactifs, avec A0 et L0 déjà propagées.
Étape 1 - Estimer le score de propension
Comme pour la G-computation, on travaille d’abord sur une base une ligne par individu (df_base) pour estimer le score de propension et les poids IPTW, puis on fusionne les poids dans df pour l’analyse de survie pondérée.
Le score de propension est \(e_i = P(A_0 = 1 \mid X = x_i,\ L_0 = l_i)\), estimé par régression logistique sur les données de la première visite.
Créez df_base (une ligne par individu), estimez le modèle de propension mod.ps et stockez les probabilités prédites dans df_base$ps.
Montrez moi comment faire !
## Base une ligne par individudf_base<-df|>group_by(id)|>summarise(A0 =first(A), L0 =first(L), X =first(X))|>ungroup()## Modèle de propension : on modélise l'exposition A0 en fonction des covariables## (à la différence de la G-computation qui modélisait l'outcome D)mod.ps<-glm(A0~X+L0, data =df_base, family ="binomial")## type = "response" : probabilités prédites P(A0=1 | X, L0), pas le log-oddsdf_base$ps<-predict(mod.ps, type ="response")## Distribution du PS par groupesummary(df_base$ps[df_base$A0==1])summary(df_base$ps[df_base$A0==0])
Voir le résultat
Min. 1st Qu. Median Mean 3rd Qu. Max.
0.05548 0.32180 0.49841 0.48745 0.64607 0.96357
Min. 1st Qu. Median Mean 3rd Qu. Max.
0.01154 0.15052 0.25941 0.29271 0.40449 0.93523
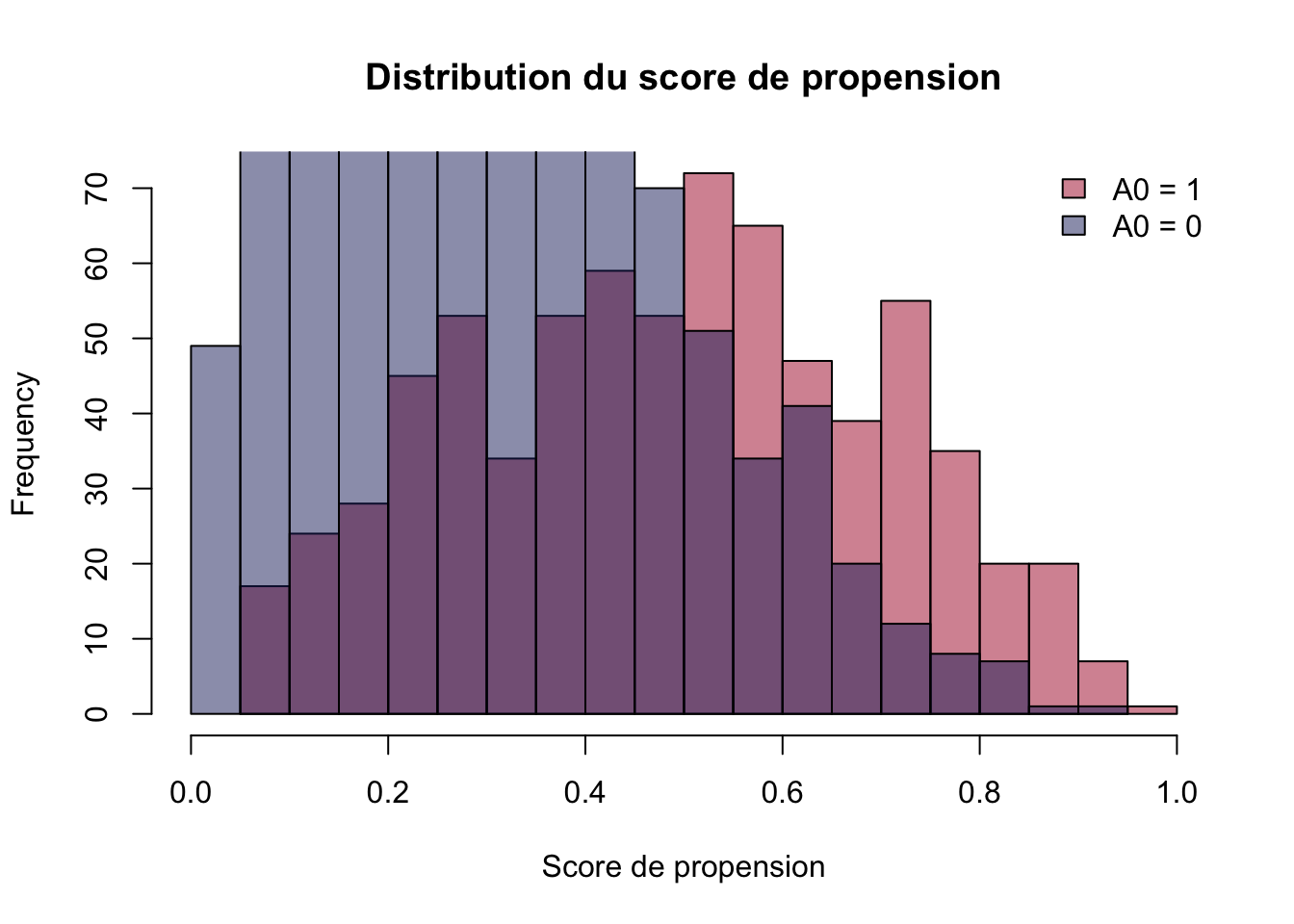
Visualisez la distribution du score de propension selon \(A_0\) pour vérifier le chevauchement (positivité) :
Montrez moi comment faire !
## Vérifier le chevauchement : si les deux distributions sont bien distinctes,## la positivité est menacée et les poids seront instableshist(df_base$ps[df_base$A0==1], breaks =20, col ="#AC182E80", main ="Distribution du score de propension", xlab ="Score de propension", xlim =c(0, 1))hist(df_base$ps[df_base$A0==0], breaks =20, col ="#1D276980", add =TRUE)legend("topright", legend =c("A0 = 1", "A0 = 0"), fill =c("#AC182E80", "#1D276980"), bty ="n")
Voir le résultat
Étape 2 - Calculer les poids IPTW
On calcule les poids non stabilisés\(w_i = A_0/e_i + (1-A_0)/(1-e_i)\) et les poids stabilisés\(w^s_i = P(A_0)/e_i\) si \(A_0=1\), \(P(A_0=0)/(1-e_i)\) si \(A_0=0\), sur df_base. On fusionne ensuite les poids dans df pour l’analyse de survie pondérée.
Calculez df_base$iptw (non stabilisé) et df_base$iptw.s (stabilisé), puis fusionnez dans df.
Montrez moi comment faire !
## Poids non stabilisés : w = 1/ps si exposé, 1/(1-ps) si non exposédf_base$iptw<-(df_base$A0==1)/df_base$ps+(df_base$A0==0)/(1-df_base$ps)## Numérateur des poids stabilisés : probabilité marginale d'exposition## (sans covariables) — réduit la variance des poids par rapport aux non stabilisésp.A1<-mean(df_base$A0)p.A0<-1-p.A1## Poids stabilisés : w^s = P(A0) / ps si exposé, P(1-A0) / (1-ps) si non exposédf_base$iptw.s<-ifelse(df_base$A0==1,p.A1/df_base$ps,p.A0/(1-df_base$ps))## Les poids stabilisés ont une moyenne proche de 1 : vérifier des valeurs## extrêmes (> 10-20) qui signaleraient un problème de positivitécat("Poids non stabilisés - moyenne:", round(mean(df_base$iptw), 3)," / max:", round(max(df_base$iptw), 2), "\n")cat("Poids stabilisés - moyenne:", round(mean(df_base$iptw.s), 3)," / max:", round(max(df_base$iptw.s), 2), "\n")## Fusionner dans df (format long) pour l'analyse de survie pondéréedf<-df|>left_join(df_base|>select(id, ps, iptw, iptw.s), by ="id")
Voir le résultat
Poids non stabilisés - moyenne: 2.003 / max: 18.02
Poids stabilisés - moyenne: 1 / max: 9.83
Note
Règle pratique : les poids stabilisés ont une moyenne proche de 1 et une variance plus faible. Ils sont généralement préférés en pratique. Si certains poids sont très élevés (> 10–20), c’est un signe de violation de la positivité ou d’un modèle de propension mal spécifié.
Étape 3 - Vérifier l’équilibre
Avant toute analyse, il faut s’assurer que la pondération a rétabli l’équilibre entre les groupes \(A_0=1\) et \(A_0=0\) sur les covariables \(X\) et \(L_0\).
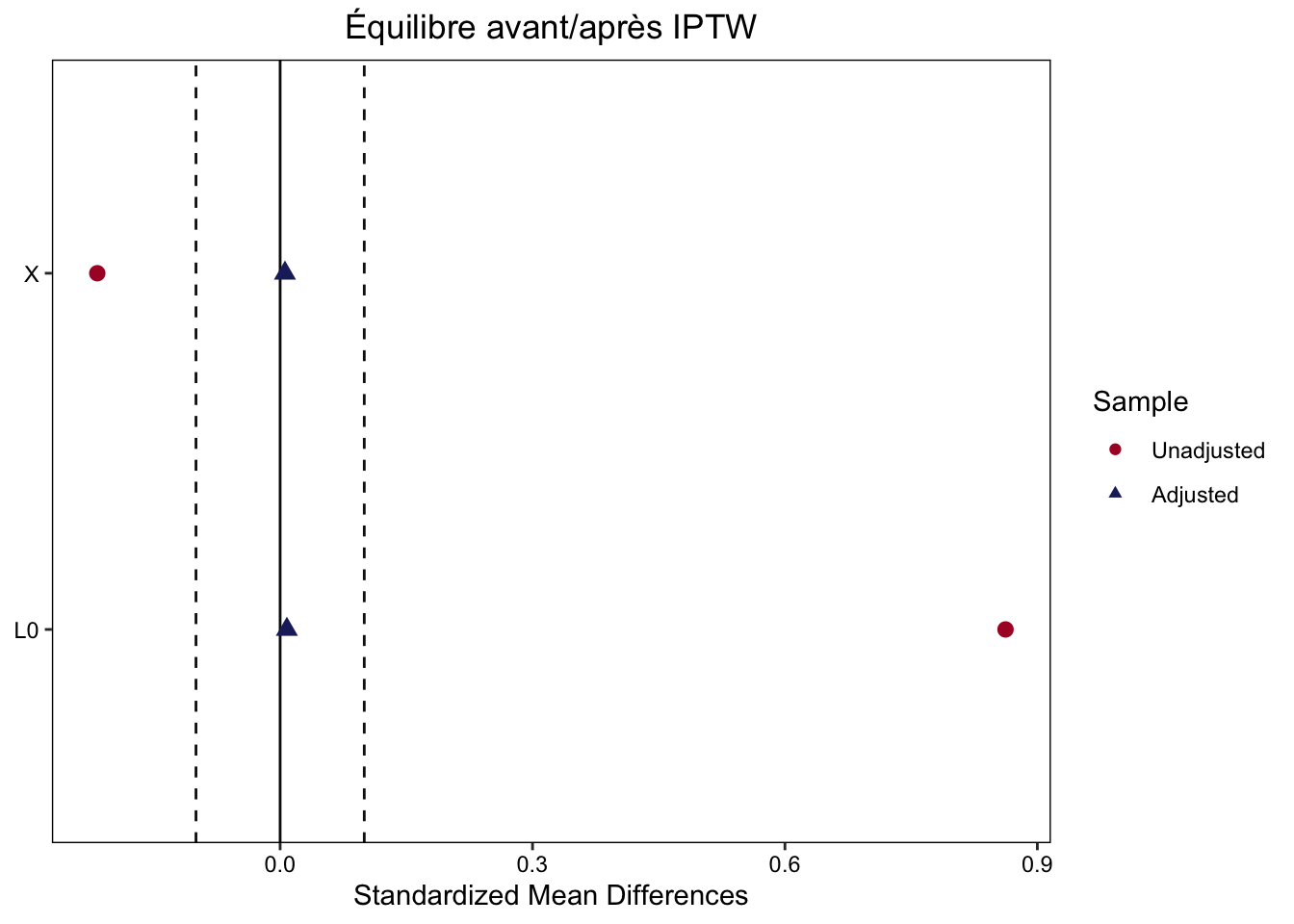
library(cobalt)## bal.tab() : différences standardisées (SMD) pour chaque covariable## binary = "std" : SMD pour les variables binaires, un = TRUE : affiche aussi avant pondérationbal<-bal.tab(A0~X+L0, data =df_base, weights =df_base$iptw.s, method ="weighting", binary ="std", un =TRUE)bal## Love plot : SMD < 0,1 après pondération indique un équilibre satisfaisantlove.plot(bal, thresholds =c(m =0.1), colors =c("#AC182E", "#1D2769"), shapes =c("circle", "triangle"), title ="Équilibre avant/après IPTW")
Voir le résultat
Note: `s.d.denom` not specified; assuming "pooled".
Balance Measures
Type Diff.Un Diff.Adj
X Binary -0.2173 0.0057
L0 Contin. 0.8622 0.0080
Effective sample sizes
Control Treated
Unadjusted 1273. 727.
Adjusted 1036.41 451.57
Les différences standardisées après pondération sont-elles inférieures à 0,1 (seuil conventionnel) ?
AstuceRéponse
Si les SMD après pondération sont < 0,1 pour toutes les covariables, l’équilibre est satisfaisant. Un SMD résiduel > 0,1 suggère une mauvaise spécification du modèle de propension (variables manquantes, transformations nécessaires, interactions, etc.).
Rappel : n’utilisez pas de p-values pour évaluer l’équilibre : elles dépendent de la taille d’échantillon et ne mesurent pas la comparabilité des groupes.
Étape 4 - Analyse de survie pondérée (Kaplan-Meier)
Estimez les courbes de Kaplan-Meier pondérées par iptw.s, tracez-les et obtenez la différence de survie à 3 ans.
Montrez moi comment faire !
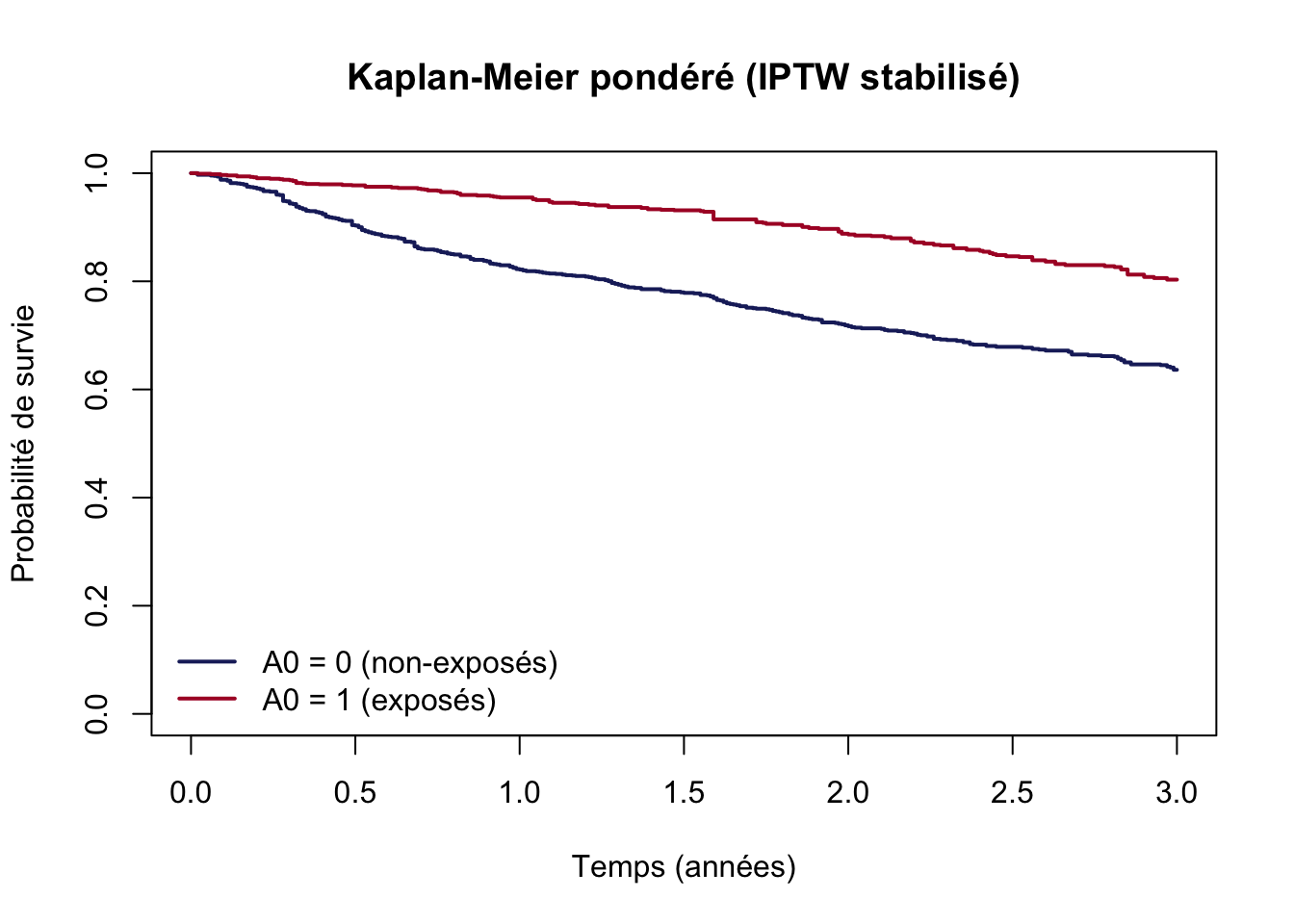
## Surv(T.start, T.stop, D) : format comptage (plusieurs lignes par individu)## weights = iptw.s : chaque observation est pondérée par son poids IPTW stabilisékm.iptw<-survfit(Surv(T.start, T.stop, D)~A0, data =df, weights =iptw.s)plot(km.iptw, col =c("#1D2769", "#AC182E"), lwd =2, conf.int =FALSE, xlab ="Temps (années)", ylab ="Probabilité de survie", main ="Kaplan-Meier pondéré (IPTW stabilisé)")legend("bottomleft", legend =c("A0 = 0 (non-exposés)", "A0 = 1 (exposés)"), col =c("#1D2769", "#AC182E"), lwd =2, bty ="n")## Différence de survie à 3 ans (S^(a0=1)(3) - S^(a0=0)(3))s3<-summary(km.iptw, times =3)$survcat("S(3 | a0=0) =", round(s3[1], 3), "\n")cat("S(3 | a0=1) =", round(s3[2], 3), "\n")cat("Diff. survie = S(a0=1) - S(a0=0) =", round(s3[2]-s3[1], 3), "\n")
Voir le résultat
S(3 | a0=0) = 0.636
S(3 | a0=1) = 0.803
Diff. survie = S(a0=1) - S(a0=0) = 0.167
La différence de survie à 3 ans \(S^{a_0=1}(3) - S^{a_0=0}(3)\) après IPTW est 0.167.
Comparaison G-computation vs IPTW
Les deux méthodes spécifient des modèles distincts pour répondre à la même question causale :
G-computation (Partie 1)
IPTW (cette partie)
Modèle estimé
Outcome : \(E(D \mid A_0, X, L_0)\)
Exposition : \(P(A_0=1 \mid X, L_0)\)
Critère utilisé
Binaire (simplification)
Survie censurée (complet)
Mesure d’effet
\(E(D^1) - E(D^0)\) (diff. de risque de décès)
\(S^{a_0=1}(3) - S^{a_0=0}(3)\) (diff. de survie)
Estimée
-0.135
0.167
Puisque \(P(D=1) = 1 - S(3)\), la différence de risque de décès et la différence de survie sont de signes opposés et de valeur absolue proche. L’exercice ci-dessous permet de le vérifier en calculant l’IPTW sur critère binaire (comparable à la G-computation de la Partie 1).
À partir de df_base (une ligne par individu, avec D final et iptw.s), calculez l’ATE par IPTW avec critère binaire, et vérifiez sa cohérence avec la différence de survie du KM pondéré.
Avertissement
km.iptw doit avoir été calculé à l’Étape 4 pour que ce chunk fonctionne.
Montrez moi comment faire !
## D final : statut décès à la fin du suivi (dernière ligne par individu)df_base$D<-df|>group_by(id)|>summarise(D =last(D))|>pull(D)## Moyenne pondérée de D dans chaque groupe : équivalent IPTW du critère binairem1_bin<-weighted.mean(df_base$D[df_base$A0==1],df_base$iptw.s[df_base$A0==1])m0_bin<-weighted.mean(df_base$D[df_base$A0==0],df_base$iptw.s[df_base$A0==0])ate_iptw_bin<-m1_bin-m0_bincat("=== IPTW (critère binaire) ===\n")cat("E(D^1) =", round(m1_bin, 3), "\n")cat("E(D^0) =", round(m0_bin, 3), "\n")cat("ATE = E(D^1) - E(D^0) =", round(ate_iptw_bin, 3), "\n\n")s3<-summary(km.iptw, times =3)$survcat("=== IPTW (KM pondéré, critère censuré) ===\n")cat("S(3 | a0=1) =", round(s3[2], 3), "\n")cat("S(3 | a0=0) =", round(s3[1], 3), "\n")cat("Diff. survie = S(1) - S(0) =", round(s3[2]-s3[1], 3), "\n\n")cat("=== Vérification du lien ATE ≈ -diff(survie) ===\n")cat("ATE + diff(survie) =", round(ate_iptw_bin+(s3[2]-s3[1]), 3)," (doit être proche de 0)\n")
Voir le résultat
=== IPTW (critère binaire) ===
E(D^1) = 0.124
E(D^0) = 0.275
ATE = E(D^1) - E(D^0) = -0.15
=== IPTW (KM pondéré, critère censuré) ===
S(3 | a0=1) = 0.803
S(3 | a0=0) = 0.636
Diff. survie = S(1) - S(0) = 0.167
=== Vérification du lien ATE ≈ -diff(survie) ===
ATE + diff(survie) = 0.016 (doit être proche de 0)
AstuceÀ retenir
Les estimations obtenues sont :
G-computation (binaire, Partie 1) : ATE \(\approx\) -0.135
IPTW (binaire) : ATE \(\approx\) -0.15
IPTW (KM pondéré, survie) : diff. de survie \(\approx\) 0.167
Critère censuré vs binaire : la différence de survie par KM pondéré est l’estimateur de référence de cette partie, car il exploite toute l’information temporelle et traite correctement la censure. La version binaire est proposée uniquement pour le parallèle avec la Partie 1.
La Partie 3 passe à la Question 2 : l’effet de l’exposition maintenue tout au long du suivi.
Pour continuer, cliquez sur IPCW dans le menu à gauche.
BONUS - Intervalle de confiance par bootstrap
Note
Cette section est à faire chez vous, à votre rythme. Elle n’est pas traitée en TP.
Le bootstrap sert ici uniquement à estimer un intervalle de confiance autour de la différence de survie calculée à l’Étape 4 : il ne modifie pas l’estimation elle-même.
Pour les données en format long, le bootstrap ré-échantillonne des individus (pas des lignes) afin de préserver la structure temporelle. Chaque individu sélectionné reçoit un nouvel identifiant unique pour éviter les doublons.
Estimez un intervalle de confiance à 95% par bootstrap (\(B = 200\) ré-échantillons) pour la différence de survie à 3 ans estimée par IPTW.
Montrez moi comment faire !
set.seed(123)B<-200diff_boot<-numeric(B)ids<-unique(df$id)for(bin1:B){## 1. Ré-échantillonnage par individu avec nouveaux IDs uniquesids_b<-sample(ids, replace =TRUE)df_b<-do.call(rbind, lapply(seq_along(ids_b), function(j){rows<-df[df$id==ids_b[j], ]rows$id<-j# nouvel ID unique pour éviter les doublonsrows}))## 2. Base une ligne par individu et score de propensiondf_base_b<-df_b|>group_by(id)|>summarise(A0 =first(A), L0 =first(L), X =first(X))|>ungroup()mod_b<-glm(A0~X+L0, data =df_base_b, family ="binomial")df_base_b$ps<-predict(mod_b, type ="response")## 3. Poids IPTW stabilisés et fusion dans df_b## (on supprime d'abord les anciens poids hérités de df pour éviter les conflits)p.A1_b<-mean(df_base_b$A0)df_base_b$iptw.s<-ifelse(df_base_b$A0==1,p.A1_b/df_base_b$ps,(1-p.A1_b)/(1-df_base_b$ps))df_b<-df_b|>select(-any_of(c("ps", "iptw", "iptw.s")))|>left_join(df_base_b|>select(id, iptw.s), by ="id")## 4. KM pondéré et différence de survie à 3 anskm_b<-survfit(Surv(T.start, T.stop, D)~A0, data =df_b, weights =iptw.s)s3_b<-summary(km_b, times =3)$survdiff_boot[b]<-s3_b[2]-s3_b[1]}## L'estimée est celle de l'Étape 4, pas la moyenne des bootstrapcat("Différence de survie à 3 ans (IPTW) :\n")cat(" Estimée :", round(s3[2]-s3[1], 3), "\n")cat(" IC 95% :", round(quantile(diff_boot, c(0.025, 0.975)), 3), "\n")