Les Parties 1 et 2 ont estimé l’effet de l’initiation de l’exposition \(A_0\), sans se préoccuper de ce qui se passe ensuite (les patients peuvent arrêter ou débuter le traitement par la suite). C’est l’analogue-ITT.
Cette partie répond à une nouvelle question : quel serait l’effet si les patients avaient maintenu leur stratégie d’exposition tout au long du suivi ?
Stratégie : grouper les individus selon \(A_0\), puis censurer artificiellement tout individu qui dévie de sa stratégie initiale. Cette censure est très probablement informative (les patients qui changent de traitement diffèrent des autres) → on corrige par IPCW. Les poids IPTW de la Partie 2 sont conservés pour l’équilibre initial.
Note sur la session R
Les variables suivantes sont disponibles dans vos chunks interactifs (reconstruites dans le contexte de setup) :
df : base avec A0, L0 propagés
df$ps : score de propension \(P(A_0=1 \mid X, L_0)\)
df$iptw.s : poids IPTW stabilisés (de la Partie 2)
Étape 1 - Définir les deux groupes de stratégie
Créez df.1 (individus avec A0 == 1) et df.0 (individus avec A0 == 0).
Montrez moi comment faire !
## On sépare les individus selon leur stratégie initiale A0 :## les poids IPCW et la censure artificielle seront calculés séparément## dans chaque groupe (déviation = arrêt pour df.1, initiation pour df.0)df.1<-df[df$A0==1, ]df.0<-df[df$A0==0, ]cat("Individus avec A0=1 :", length(unique(df.1$id)), "\n")cat("Individus avec A0=0 :", length(unique(df.0$id)), "\n")
Voir le résultat
Individus avec A0=1 : 727
Individus avec A0=0 : 1273
Étape 2 - Censure artificielle dans le groupe A0 = 1
Pour la stratégie \(\bar{a} = 1\), un individu dévie dès qu’il arrête le traitement (\(A = 0\) à une visite ultérieure).
Dans df.1, créez switchA : 0 tant que l’individu suit la stratégie, 1 à la première déviation. Conservez toutes les lignes jusqu’à switchA ≤ 1 (on garde la ligne de déviation pour estimer le modèle de poids).
Montrez moi comment faire !
df.1<-df.1|>group_by(id)|>mutate(## cumsumA compte le nombre de visites où A=1 depuis le début cumsumA =cumsum(A==1),## Si l'individu n'a jamais dévié, cumsumA = nombre de visites écoulées = T.start + 1## Si cumsumA < T.start + 1, il y a eu au moins une visite avec A=0 -> déviation switchA =if_else(cumsumA==T.start+1, 0L, 1L),## cumsum(switchA) : une fois la déviation détectée, switchA reste >= 1 switchA =cumsum(switchA))|>filter(switchA<=1)|># garder jusqu'à la première déviation incluseungroup()table(df.1$switchA)
Voir le résultat
0 1
1038 377
Étape 3 - Modèle de déviation et poids IPCW (groupe A0 = 1)
On estime la probabilité de ne pas dévier à chaque visite par régression logistique poolée (pooled logistic regression), puis on calcule les poids IPCW :
Ajustez wt.mod.1 <- glm(switchA ~ as.factor(T.start) + X + L, ...) sur df.1, stockez wt.denom = \(P(\text{switch}=0)\) prédit. Pour les poids stabilisés, estimez un second modèle sans covariables (wt.mod.1.num). Supprimez les lignes switchA == 1. Calculez wt (non stabilisé) et wt.s (stabilisé).
Montrez moi comment faire !
## Régression logistique poolée : modélise P(switch=1) à chaque visite## as.factor(T.start) : effet du temps, X et L : covariables de confusionwt.mod.1<-glm(switchA~as.factor(T.start)+X+L, family ="binomial", data =df.1)## 1 - predict(...) : probabilité de NE PAS dévier à cette visitedf.1$wt.denom<-1-predict(wt.mod.1, type ="response", newdata =df.1)## Numérateur : même modèle sans covariables (probabilité marginale de ne pas dévier)wt.mod.1.num<-glm(switchA~as.factor(T.start), family ="binomial", data =df.1)df.1$wt.num<-1-predict(wt.mod.1.num, type ="response", newdata =df.1)## Supprimer la ligne de déviation : on ne garde que les périodes sans déviationdf.1<-df.1[df.1$switchA==0, ]## cumprod : produit cumulé des termes période par période -> poids croissant dans le tempsdf.1<-df.1|>group_by(id)|>mutate(wt =cumprod(1/wt.denom), # non stabilisé wt.s =cumprod(wt.num/wt.denom))|># stabiliséungroup()cat("Poids non stabilisés - moy:", round(mean(df.1$wt), 3)," / max:", round(max(df.1$wt), 2), "\n")cat("Poids stabilisés - moy:", round(mean(df.1$wt.s), 3)," / max:", round(max(df.1$wt.s), 2), "\n")
Voir le résultat
Poids non stabilisés - moy: 1.52 / max: 15.31
Poids stabilisés - moy: 0.991 / max: 3.35
Warning: glm.fit : l'algorithme n'a pas convergé
Warning: glm.fit : l'algorithme n'a pas convergé
Étape 4 - Répéter pour le groupe A0 = 0
Reproduire les étapes 2 et 3 pour df.0 (déviation = passer de \(A=0\) à \(A=1\)). Empiler ensuite df.1 et df.0 dans dfpp.
Montrez moi comment faire !
## Même logique que pour df.1, mais la déviation est ici A=1 (passage de 0 à 1)## cumsumA compte donc le nombre de visites où A=0df.0<-df.0|>group_by(id)|>mutate( cumsumA =cumsum(A==0), switchA =if_else(cumsumA==T.start+1, 0L, 1L), switchA =cumsum(switchA))|>filter(switchA<=1)|>ungroup()## Modèle poolé de déviation dans df.0 (avec covariables)wt.mod.0<-glm(switchA~as.factor(T.start)+X+L, family ="binomial", data =df.0)df.0$wt.denom<-1-predict(wt.mod.0, type ="response", newdata =df.0)## Numérateur (sans covariables)wt.mod.0.num<-glm(switchA~as.factor(T.start), family ="binomial", data =df.0)df.0$wt.num<-1-predict(wt.mod.0.num, type ="response", newdata =df.0)df.0<-df.0[df.0$switchA==0, ]df.0<-df.0|>group_by(id)|>mutate(wt =cumprod(1/wt.denom), wt.s =cumprod(wt.num/wt.denom))|>ungroup()## Empilementdfpp<-rbind(df.1, df.0)cat("Lignes dans dfpp :", nrow(dfpp), "\n")
Voir le résultat
Lignes dans dfpp : 3272
Warning: glm.fit : l'algorithme n'a pas convergé
Warning: glm.fit : l'algorithme n'a pas convergé
Étape 5 - Poids combinés IPTW × IPCW
Les poids IPCW (wt) corrigent la censure artificielle informative. Mais ils ne rééquilibrent pas encore les caractéristiques initiales entre \(A_0=1\) et \(A_0=0\). Il faut combiner avec les poids IPTW estimés en Partie 2.
Calculez dfpp$comb.wt = dfpp$iptw.s * dfpp$wt.s (poids combinés stabilisés), puis vérifiez la distribution.
Montrez moi comment faire !
## IPTW corrige la confusion initiale, IPCW corrige la censure informative## Les deux biais étant indépendants, leurs corrections se multiplientdfpp$comb.wt<-dfpp$iptw.s*dfpp$wt.scat("Poids IPCW stabilisés - moy:", round(mean(dfpp$wt.s), 3)," / max:", round(max(dfpp$wt.s), 2), "\n")cat("Poids combinés - moy:", round(mean(dfpp$comb.wt), 3)," / max:", round(max(dfpp$comb.wt), 2), "\n")
Voir le résultat
Poids IPCW stabilisés - moy: 1 / max: 1
Poids combinés - moy: 0.977 / max: 9.83
Note
Pourquoi multiplier ? Les poids IPTW rééquilibrent les groupes sur les caractéristiques initiales (\(X\), \(L_0\)). Les poids IPCW compensent la censure artificielle informative au cours du suivi (\(L_t\), \(A_t\)). Les deux sources de biais sont indépendantes, donc leurs corrections se multiplient.
Étape 6 - Analyse de survie per-protocol
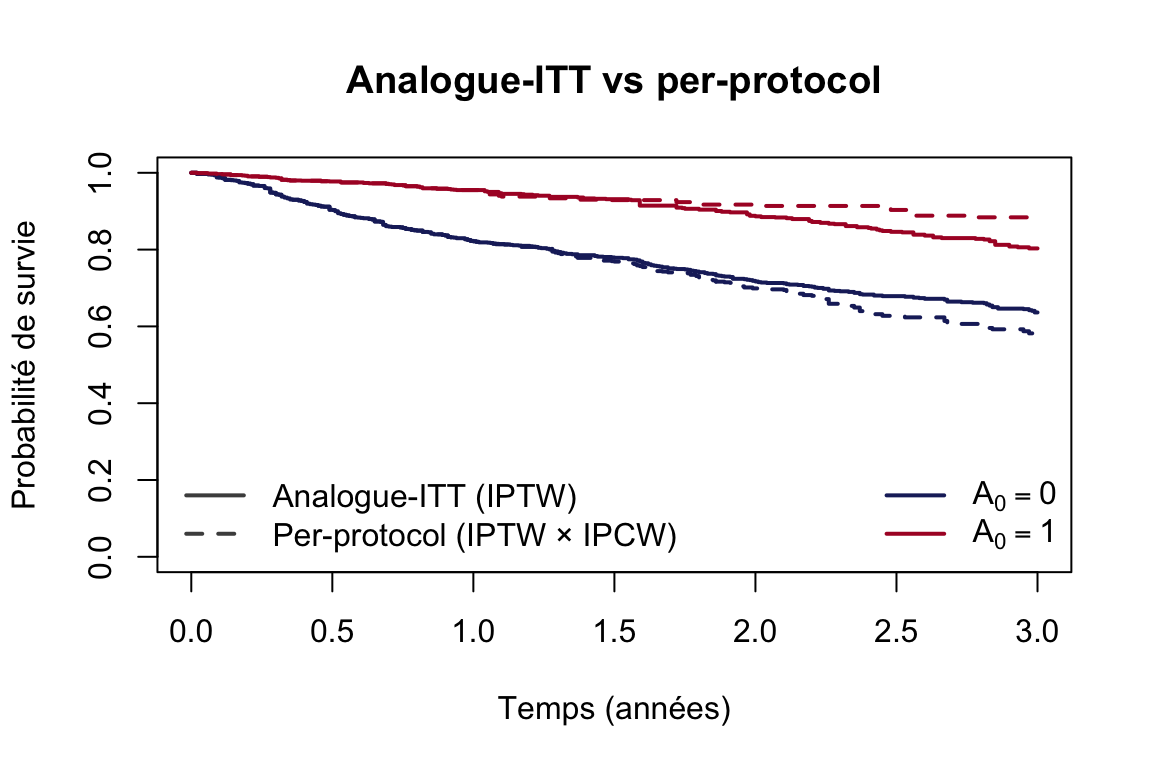
Tracez le Kaplan-Meier pondéré par comb.wt dans dfpp. Comparez avec l’analogue-ITT de la Partie 2.
Montrez moi comment faire !
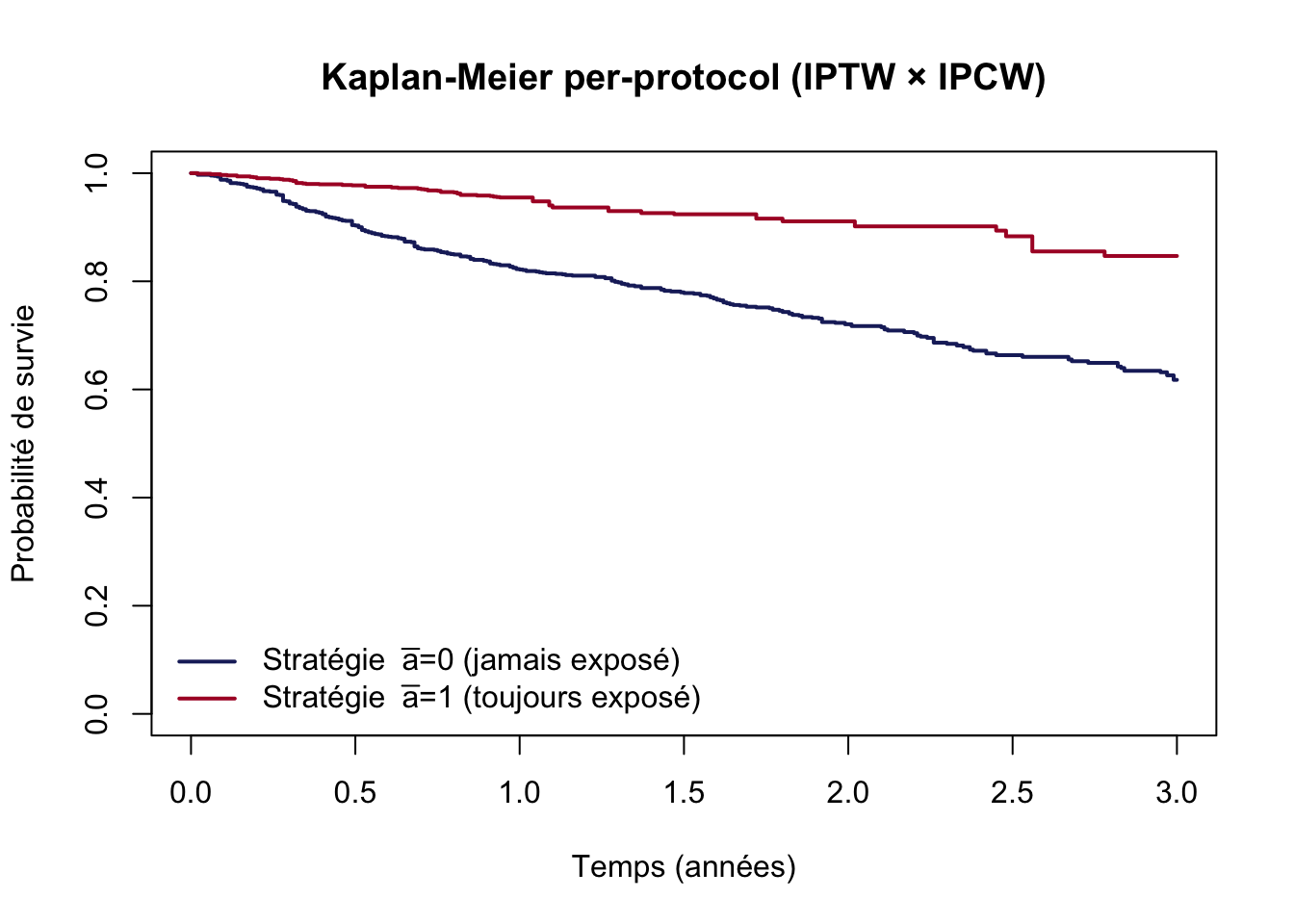
## dfpp contient les deux groupes après censure artificielle## comb.wt = IPTW × IPCW : corrige à la fois la confusion et la censure informativekm.pp<-survfit(Surv(T.start, T.stop, D)~A0, data =dfpp, weights =comb.wt)plot(km.pp, col =c("#1D2769", "#AC182E"), lwd =2, conf.int =FALSE, xlab ="Temps (années)", ylab ="Probabilité de survie", main ="Kaplan-Meier per-protocol (IPTW × IPCW)")legend("bottomleft", legend =expression("Stratégie "~bar(a)*"=0 (jamais exposé)","Stratégie "~bar(a)*"=1 (toujours exposé)"), col =c("#1D2769", "#AC182E"), lwd =2, bty ="n")## Différence de survie à 3 ans (ā=1 moins ā=0)s3.pp<-summary(km.pp, times =3)$survcat("Survie à 3 ans - ā=0 :", round(s3.pp[1], 3), "\n")cat("Survie à 3 ans - ā=1 :", round(s3.pp[2], 3), "\n")cat("Différence S(ā=1) - S(ā=0) :", round(s3.pp[2]-s3.pp[1], 3), "\n")
Voir le résultat
Survie à 3 ans - ā=0 : 0.618
Survie à 3 ans - ā=1 : 0.847
Différence S(ā=1) - S(ā=0) : 0.229
La différence de survie à 3 ans \(S^{\bar{a}=1}(3) - S^{\bar{a}=0}(3)\) (per-protocol) est 0.229.
Interprétation
Comparez l’effet per-protocol à l’effet analogue-ITT. Pourquoi peut-il différer ?
AstuceRéponse
L’analogue-ITT estime l’effet d’initier l’exposition \(A_0\), quelle que soit la compliance ultérieure. Il dilue l’effet si certains exposés arrêtent leur traitement.
L’analogue per-protocol estime l’effet de maintenir l’exposition tout au long du suivi. Il peut être plus fort (si l’exposition continue est nécessaire) ou différent pour d’autres raisons.
Si les deux estimations convergent, l’arrêt du traitement n’a pas d’impact majeur sur la survie. Si elles divergent, la compliance joue un rôle.
Hypothèses supplémentaires nécessaires pour l’analogue-PP :
Échangeabilité conditionnelle au cours du temps : \(L_t\) capture tous les facteurs qui prédisent à la fois la déviation et le décès.
Positivité au cours du temps : à chaque visite, chaque individu doit avoir une probabilité positive de continuer ou d’arrêter.
Pour continuer, cliquez sur Conclusion dans le menu à gauche.
BONUS - Intervalle de confiance par bootstrap
Note
Cette section est à faire chez vous, à votre rythme. Elle n’est pas traitée en TP. La boucle bootstrap est plus longue qu’en Parties 1 et 2 car elle refait toute la chaîne d’analyse (IPTW + censure artificielle + IPCW) à chaque itération.
Le bootstrap sert ici uniquement à estimer un intervalle de confiance autour de la différence de survie per-protocol calculée à l’Étape 6 : il ne modifie pas l’estimation elle-même.
Comme en Partie 2, le bootstrap ré-échantillonne des individus (pas des lignes) avec attribution de nouveaux identifiants uniques.
Estimez un intervalle de confiance à 95% par bootstrap (\(B = 200\) ré-échantillons) pour la différence de survie à 3 ans per-protocol.
Montrez moi comment faire !
set.seed(42)B<-200diff_boot<-numeric(B)ids<-unique(df$id)for(bin1:B){## 1. Ré-échantillonnage par individu avec nouveaux IDs uniquesids_b<-sample(ids, replace =TRUE)df_b<-do.call(rbind, lapply(seq_along(ids_b), function(j){rows<-df[df$id==ids_b[j], ]rows$id<-jrows}))## 2. IPTW : score de propension et poids stabilisésdf_base_b<-df_b|>group_by(id)|>summarise(A0 =first(A), L0 =first(L), X =first(X))|>ungroup()mod_b<-glm(A0~X+L0, data =df_base_b, family ="binomial")df_base_b$ps<-predict(mod_b, type ="response")p.A1_b<-mean(df_base_b$A0)df_base_b$iptw.s<-ifelse(df_base_b$A0==1,p.A1_b/df_base_b$ps,(1-p.A1_b)/(1-df_base_b$ps))## Supprimer les anciens poids hérités de df avant de joindre les nouveauxdf_b<-df_b|>select(-any_of(c("ps", "iptw", "iptw.s")))|>left_join(df_base_b|>select(id, iptw.s), by ="id")## 3. Censure artificielle et poids IPCW stabilisés pour la stratégie ā=1df1_b<-df_b[df_b$A0==1, ]|>group_by(id)|>mutate(cumsumA =cumsum(A==1), switchA =if_else(cumsumA==T.start+1, 0L, 1L), switchA =cumsum(switchA))|>filter(switchA<=1)|>ungroup()wt1_b<-glm(switchA~as.factor(T.start)+X+L, family ="binomial", data =df1_b)wt1_num_b<-glm(switchA~as.factor(T.start), family ="binomial", data =df1_b)df1_b$wt.denom<-1-predict(wt1_b, type ="response", newdata =df1_b)df1_b$wt.num<-1-predict(wt1_num_b, type ="response", newdata =df1_b)df1_b<-df1_b[df1_b$switchA==0, ]|>group_by(id)|>mutate(wt.s =cumprod(wt.num/wt.denom))|>ungroup()## 4. Censure artificielle et poids IPCW stabilisés pour la stratégie ā=0df0_b<-df_b[df_b$A0==0, ]|>group_by(id)|>mutate(cumsumA =cumsum(A==0), switchA =if_else(cumsumA==T.start+1, 0L, 1L), switchA =cumsum(switchA))|>filter(switchA<=1)|>ungroup()wt0_b<-glm(switchA~as.factor(T.start)+X+L, family ="binomial", data =df0_b)wt0_num_b<-glm(switchA~as.factor(T.start), family ="binomial", data =df0_b)df0_b$wt.denom<-1-predict(wt0_b, type ="response", newdata =df0_b)df0_b$wt.num<-1-predict(wt0_num_b, type ="response", newdata =df0_b)df0_b<-df0_b[df0_b$switchA==0, ]|>group_by(id)|>mutate(wt.s =cumprod(wt.num/wt.denom))|>ungroup()## 5. Poids combinés et KM per-protocoldfpp_b<-rbind(df1_b, df0_b)dfpp_b$comb.wt<-dfpp_b$iptw.s*dfpp_b$wt.skm_b<-survfit(Surv(T.start, T.stop, D)~A0, data =dfpp_b, weights =comb.wt)s3_b<-summary(km_b, times =3)$survdiff_boot[b]<-s3_b[2]-s3_b[1]}## L'estimée est celle de l'Étape 6, pas la moyenne des bootstrapcat("Différence de survie à 3 ans (per-protocol) :\n")cat(" Estimée :", round(s3.pp[2]-s3.pp[1], 3), "\n")cat(" IC 95% :", round(quantile(diff_boot, c(0.025, 0.975)), 3), "\n")
Voir le résultat
Différence de survie à 3 ans (per-protocol) :
Estimée : 0.229
IC 95% : 0.252 0.378
BONUS 2 - Clonage, censure, pondération : IPCW seul
Note
Cette section illustre ce qui a été dit en cours : dans l’approche par clonage, l’IPCW seul suffit — sans IPTW. La clé est que le modèle IPCW inclut les observations au temps 0 où la déviation immédiate est exactement le complément du score de propension. Pour cela, les modèles doivent être ajustés séparément dans chaque groupe de clones : à T.start = 0, les effets de X et L sur la déviation sont de sens opposés entre les deux stratégies, et un modèle commun annulerait ces effets.
Code
## ── Étape 1 : Cloner ────────────────────────────────────────────────────────## Chaque individu reçoit deux clones : un assigné à la stratégie ā=1, l'autre ā=0df.c1<-df; df.c1$strategy<-1df.c0<-df; df.c0$strategy<-0df.clone<-rbind(df.c1, df.c0)## ── Étape 2 : Censure artificielle selon la stratégie assignée ───────────────df.clone<-df.clone|>group_by(id, strategy)|>mutate( cumsumA =if_else(strategy==1, cumsum(A==1), cumsum(A==0)), switchA =if_else(cumsumA==T.start+1, 0L, 1L), switchA =cumsum(switchA))|>filter(switchA<=1)|>ungroup()## ── Étape 3 : IPCW seul, modèles séparés par groupe de clones ───────────────## À T.start = 0, strategy = 1 : déviation = I(A = 0) → P(pas de déviation | X, L) = P(A=1|X,L)## À T.start = 0, strategy = 0 : déviation = I(A = 1) → P(pas de déviation | X, L) = P(A=0|X,L)## Le terme T.start = 0 du modèle par groupe absorbe exactement le poids IPTW.## Les modèles DOIVENT être séparés car les effets de X et L sont opposés.dc1<-df.clone[df.clone$strategy==1, ]dc0<-df.clone[df.clone$strategy==0, ]wd1<-glm(switchA~as.factor(T.start)+X+L, family ="binomial", data =dc1)wn1<-glm(switchA~as.factor(T.start), family ="binomial", data =dc1)dc1$wt.denom<-1-predict(wd1, type ="response", newdata =dc1)dc1$wt.num<-1-predict(wn1, type ="response", newdata =dc1)wd0<-glm(switchA~as.factor(T.start)+X+L, family ="binomial", data =dc0)wn0<-glm(switchA~as.factor(T.start), family ="binomial", data =dc0)dc0$wt.denom<-1-predict(wd0, type ="response", newdata =dc0)dc0$wt.num<-1-predict(wn0, type ="response", newdata =dc0)df.clone<-rbind(dc1, dc0)df.clone<-df.clone[df.clone$switchA==0, ]|>group_by(id, strategy)|>mutate(ipcw.s =cumprod(wt.num/wt.denom))|>ungroup()## KM pondéré IPCW seul (approche clonage)km.clone<-survfit(Surv(T.start, T.stop, D)~strategy, data =df.clone, weights =ipcw.s)
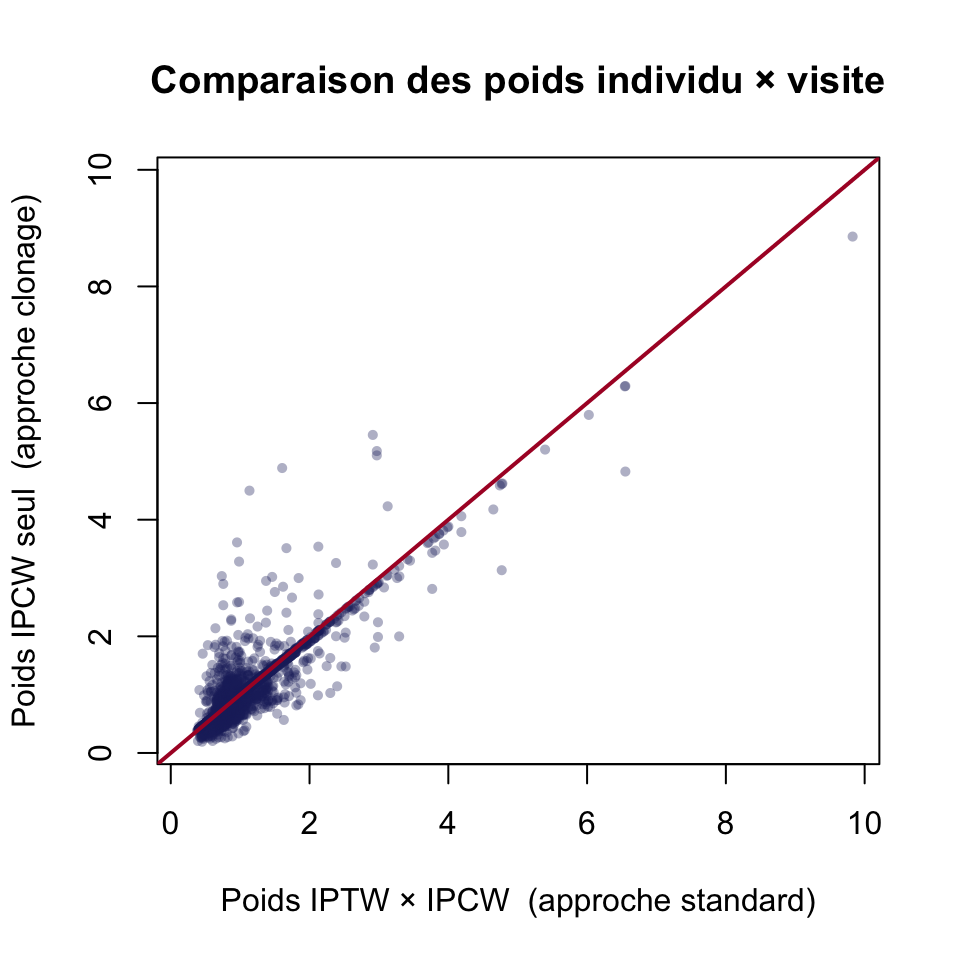
Comparaison des poids individu × visite
Les poids IPTW × IPCW (approche standard, dfpp$comb.wt) et les poids IPCW seul (approche clonage, df.clone$ipcw.s) doivent être alignés sur la diagonale si les deux approches estiment bien la même chose.
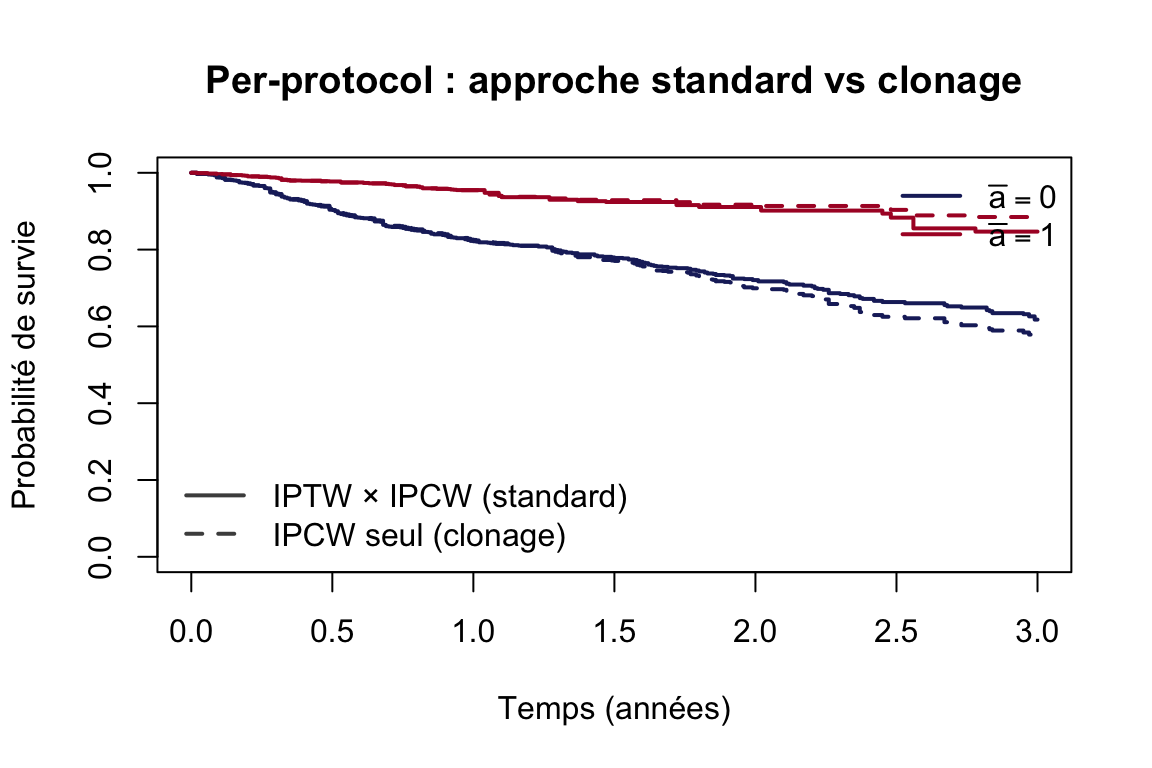
plot(km.pp, col =c(col0, col1), lwd =2, lty =1, conf.int =FALSE, ylim =c(0, 1), xlim =c(0, 3), xlab ="Temps (années)", ylab ="Probabilité de survie", main ="Per-protocol : approche standard vs clonage")lines(km.clone, col =c(col0, col1), lwd =2, lty =2, conf.int =FALSE)legend("bottomleft", lty =1:2, lwd =2, col ="gray30", bty ="n", legend =c("IPTW × IPCW (standard)", "IPCW seul (clonage)"))legend("topright", lty =1, lwd =2, col =c(col0, col1), bty ="n", legend =c(expression(bar(a)==0), expression(bar(a)==1)))
Les courbes se superposent et les poids sont alignés sur la diagonale : les deux approches estiment bien le même estimand per-protocol. Le clonage rend l’IPTW redondant car il garantit l’équilibre initial entre les groupes par construction.