Présentation des données
Présentation
Dans ce TP, nous utiliserons un jeu de données simulées (df.csv) contenant des informations sur 2000 individus suivis dans le cadre d’une étude de cohorte observationnelle. L’objectif est d’évaluer l’effet d’un traitement \(A\) (exposé/non exposé, pouvant changer au cours du temps) sur la mortalité à 3 ans.
Les données sont au format long (counting process) : chaque individu contribue une ligne par période d’observation (ici, une ligne par visite annuelle).
| Variable | Description |
|---|---|
id |
Identifiant patient |
T.start |
Début de la période d’observation (en années) |
T.stop |
Fin de la période d’observation (en années) |
A |
Traitement (0/1), dépendant du temps |
D |
Décès survenu avant T.stop (0/1) |
L |
Facteur de confusion dépendant du temps (continu) |
X |
Facteur de confusion initial (binaire 0/1, non dépendant du temps) |
⬇ Télécharger les données df.csv
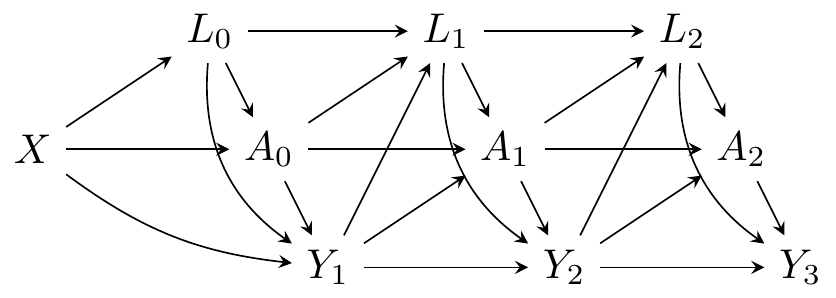
On suppose que les relations entre les variables suivent le DAG (directed acyclic graph) en temps discret ci-dessous, où \(Y_t\) désigne l’indicateur de décès à la période \(t\) (\(t = 1, 2, 3\)) :
Lecture du DAG :
- \(X\) (bleu foncé) - facteur de confusion initial : influence \(A_0\), \(L_0\) et \(Y_1\).
- \(L_t\) (bleu clair) - facteur de confusion dépendant du temps : influencé par le traitement passé \(A_{t-1}\) et l’état de santé \(Y_t\), il prédit à son tour \(A_t\) et \(Y_{t+1}\).
- \(A_t\) (rouge) - exposition à chaque période, influencée par \(X\), \(L_t\) et les valeurs passées.
- \(Y_t\) (gris) - indicateur de décès, influencé par \(A_{t-1}\) et \(L_{t-1}\).
Chargement et exploration
Chargez les données et affichez les premières lignes. Vérifiez les dimensions de la base et le nombre d’individus distincts.
Voir le résultat
id visit T.start T.stop D X L A
1 1 0 0 1.00 0 0 -1.426024 0
2 1 1 1 2.00 0 0 -0.603308 1
3 1 2 2 2.21 0 0 1.095353 1
4 2 0 0 1.00 0 0 2.096532 1
5 2 1 1 2.00 0 0 -1.393365 0
6 2 2 2 2.50 0 0 -1.962157 0[1] 4376 8[1] 2000[1] 409 id visit T.start T.stop D X L A
1 1 0 0 1.00 0 0 -1.42602393 0
2 1 1 1 2.00 0 0 -0.60330795 1
3 1 2 2 2.21 0 0 1.09535346 1
4 2 0 0 1.00 0 0 2.09653237 1
5 2 1 1 2.00 0 0 -1.39336531 0
6 2 2 2 2.50 0 0 -1.96215717 0
7 3 0 0 1.00 0 0 -0.01628423 0
8 3 1 1 2.00 0 0 -2.03632041 0
9 3 2 2 2.17 1 0 0.84534380 0La base comporte 4376 lignes, 8 colonnes, 2000 individus distincts et 409 décès observés.
Note
Format long : chaque individu a autant de lignes qu’il a eu de périodes de suivi (en général 1 à 3, selon s’il est décédé ou perdu de vue précocement). La colonne T.start/T.stop délimite chaque période. Le dernier enregistrement par individu indique son statut final (\(D\)) et son temps total de suivi.
Analyse brute (non ajustée)
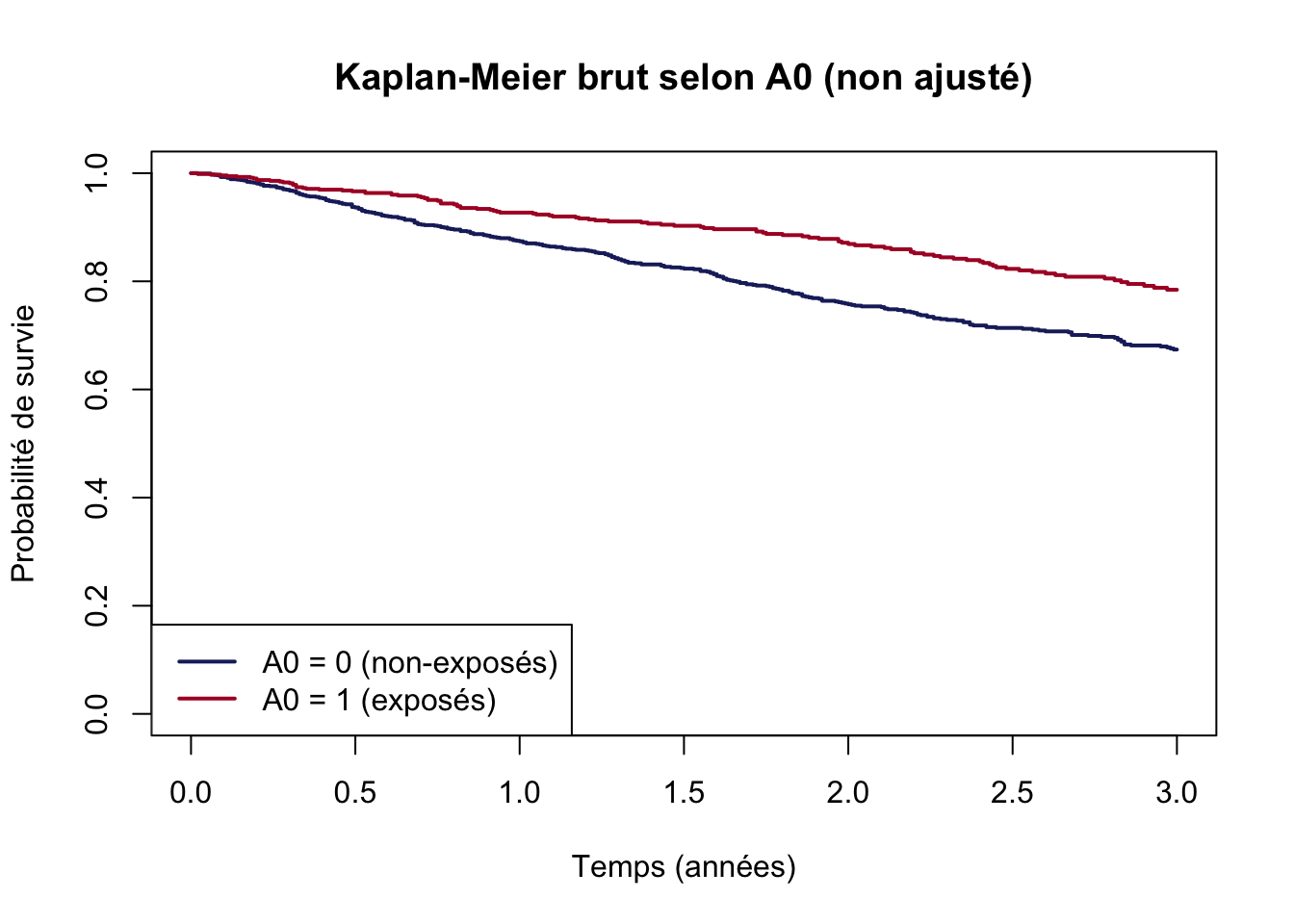
Avant tout ajustement, comparons les courbes de survie selon le traitement initial \(A_0\) (valeur de \(A\) à la première visite).
Créez la variable A0 (valeur initiale de \(A\) pour chaque individu), puis tracez les courbes de Kaplan-Meier selon A0.
Montrez moi comment faire !
## A0 : valeur de A à la première visite, propagée à toutes les lignes de l'individu
df <- df |>
group_by(id) |>
mutate(A0 = first(A)) |>
ungroup()
## Surv(T.start, T.stop, D) : format comptage pour données en format long
## (plusieurs lignes par individu, une par période de suivi)
km_brut <- survfit(Surv(T.start, T.stop, D) ~ A0, data = df)
plot(km_brut,
col = c("#1D2769", "#AC182E"), lwd = 2,
xlab = "Temps (années)", ylab = "Probabilité de survie",
main = "Kaplan-Meier brut selon A0 (non ajusté)")
legend("bottomleft",
legend = c("A0 = 0 (non-exposés)", "A0 = 1 (exposés)"),
col = c("#1D2769", "#AC182E"), lwd = 2)
## Survie à 3 ans
summary(km_brut, times = 3)Voir le résultat
Call: survfit(formula = Surv(T.start, T.stop, D) ~ A0, data = df)
A0=0
time n.risk n.event survival std.err lower 95% CI
3.0000 354.0000 304.0000 0.6738 0.0163 0.6426
upper 95% CI
0.7065
A0=1
time n.risk n.event survival std.err lower 95% CI
3.0000 212.0000 105.0000 0.7844 0.0197 0.7467
upper 95% CI
0.8241 Que constatez-vous ? Cette différence brute a-t-elle une interprétation causale ?
AstuceRéponse
On observe une différence de survie entre les groupes \(A_0 = 0\) et \(A_0 = 1\). Cependant, cette différence n’a pas d’interprétation causale car les deux groupes ne sont pas comparables : les individus traités (\(A_0 = 1\)) et non traités (\(A_0 = 0\)) diffèrent sur \(X\) et \(L_0\), qui sont à la fois des prédicteurs de l’exposition et du décès (facteurs de confusion).
Les parties suivantes montrent comment corriger ce biais par G-computation et IPTW.
Ce que nous observons, ce que nous voulons estimer
L’analyse brute met en évidence une différence de survie entre les groupes \(A_0 = 0\) et \(A_0 = 1\). Mais cette différence n’a pas d’interprétation causale directe : les deux groupes ne sont pas comparables à l’inclusion (les individus exposés et non exposés diffèrent sur \(X\) et \(L_0\), qui prédisent à la fois l’exposition et le décès).
Les parties suivantes vont estimer deux effets causaux distincts à partir de ces données :
- Parties 1 et 2 : effet de l’initiation de l’exposition au temps 0, ajusté sur les facteurs de confusion initiaux (d’abord par G-computation, puis par IPTW).
- Partie 3 : effet du maintien de l’exposition tout au long du suivi, en traitant les déviations de stratégie comme une censure artificielle (IPTW + IPCW).
Pour continuer, cliquez sur G-computation dans le menu à gauche.